Hiliting large text fields in ElasticSearch
 In December of 2016, we had begun to work new project — collection-indexing-search documents. The system is built around ElasticSearch (hereinafter — ES), which we use as the main engine for full text search.
In December of 2016, we had begun to work new project — collection-indexing-search documents. The system is built around ElasticSearch (hereinafter — ES), which we use as the main engine for full text search.
Valuable data acquired in the course of work on the project, we would like to share with readers in a series of articles about ES. Let's start with the basics any search engine — highlighting of search results (hereinafter — hiliting).
Proper highlighting of search results is perhaps the most important criterion of the effectiveness of search engines for the user. First, the logic of the visible inclusion of the document in the search results, and second, the block highlighting the found text enables you to quickly assess the context of the found hit.
One of the key requirements for our search engine was the ability to quickly and effectively work with large files (over 100 MB). In this article we will tell you how to achieve high performance from ES when hiliting large document fields.
the screenshot below shows how the highlighting of search results in our project.
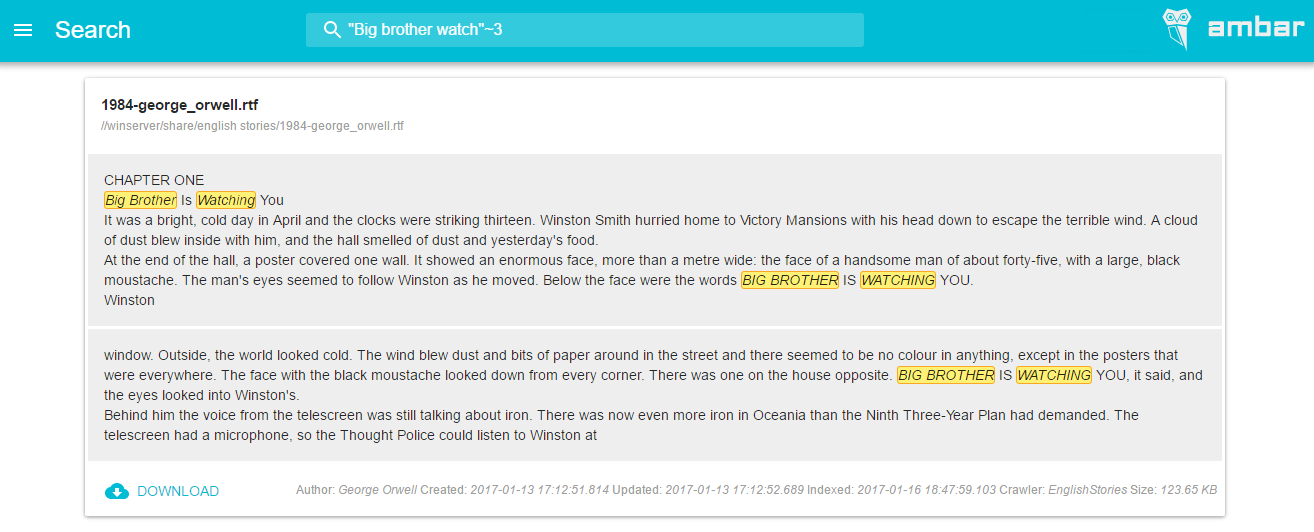
the First step or the essence of the problem
so, we use ES to store and search metadata and rasparennouu contents of the files. An example of a document that we store in ES:
the
{
sha256: "1a4ad2c5469090928a318a4d9e4f3b21cf1451c7fdc602480e48678282ced02c",
meta: [
{
id: "21264f64460498d2d3a7ab4e1d8550e4b58c0469744005cd226d431d7a5828d0",
short_name: "quarter.pdf",
full_name: "//winserver/store/reports/quarter.pdf",
source_id: "crReports",
extension: ".pdf",
created_datetime: "2017-01-14 14:49:36.788",
updated_datetime: "2017-01-14 14:49:37.140",
extra: [],
indexed_datetime: "2017-01-16 18:32:03.712"
}
],
content: {
size: 112387192, /* File is larger than 100 Mb */
indexed_datetime: "2017-01-16 18:32:33.321",
author: "John Smith",
processed_datetime: "2017-01-16 18:32:33.321",
length: "",
language: "",
state: "processed",
title: "Quarter Report (Q4Y2016)",
type: "application/pdf",
text: ".... a lot of text here ...."
}
}As you may have guessed, this rasparenny the content of a pdf file with the financial report the size of a little over 100 MB. Field content.text I intentionally shortened, it is obvious that its length is approximately equal to the most 100 MB.
we carry out a simple experiment: take 1000 such documents and indexing them ES th is not using any special settings of the index or the ES. Let's see how fast the work search and highlight on the documents.
Results
the
-
the
- Search the
match_phrasein thecontent.text: from 5 to 30 seconds.
the - Formation of highlight for the field
content.textfor each of the documents: more than 10 seconds.
This performance is no good. The user expects to see the results instantly (< 200 MS), but not in tens of seconds. Let's see how to solve the problem of slow formation of highlight. The problem of fast searching for large files, consider the following article of a cycle.
Select the algorithm hiliting
In ES it is possible to use three kinds of shimmers / highlighters. Cm. the official manual.
For those too lazy to read, on the fingers:
the
-
the
- Plain — the default, slowest, but highest quality (according to ES, almost 100% reflects the search algorithm Lucene, and it's true), for the formation of highlight unloads the entire document into memory and parses it again. the
- Postings — faster highlighter, it beats the field and pulls to highlight not all the document, and sentences where a token was found, ranging them according to the algorithm BM25. Requires enrichment of the index positions of these proposals. the
- Fast Vector Highlighting (FVH) is positioned as the fastest highlighter, especially for large documents. Requires enrichment index data on the positions of all tokens in the source document, due to this forms a highlight in almost constant time, regardless of the size of the document.
- Document size to 100 MB FVH average hilimit about 10-20 MS, Postings it spends about seconds the
- Postings are not always correctly splits the text into sentences, so the size of the highlight rides quite often (can return 50 words, maybe 300). With FVH such problem was observed. It returns the specified number of tokens in both directions from the contact the
- Postings cheilitis tokens regardless of their position, therefore highlighting phrases in this case it works correctly. For example,
simple_string_query"Ivan Ivanov"~5 soilicit not only the cases when two of the token "Smith" and "John" will be at a distance of not more than 5 tokens from each other, but all other tokens "Smith" or "John" in the specified field to the document as if it was justboolrequest tomatch"Smith" and "Ivan"
As described above, by default, ES use the Plain highlighter. So each time to generate highlights ES unloads in memory of 100 megabytes of text and that answers the query is very very slow. We have abandoned the Plain highlighter and decided to test Postings and FVH. In the end, our choice fell on FVH for several reasons:
the
-
the
the pitfalls of Fast Vector Highlighter
In the process of working with FVH we noticed the following problem: search request match_phrase "Ivan Ivanov" finds occurrences of "Ivanov Ivan" and "Ivan Ivanov", but FVH highlights only hitting in the order specified in the query. This nuance is not mentioned in any manual ES, in our opinion, this error arises from the fact that FVH takes into account the provisions of the tokens for the match_phrase of the request. Problem we decided the workaround is added to the query field highlight_query in which we move all possible positions of the tokens in the phrase. This is the only method which allowed to get all the highlights while preserving the performance at a proper level.
Result
Hilimit large documents ES can really quickly. It is important to set up an index and take into account the peculiarities of highlighter. If you solved a similar problem and found, as you think, more elegant solution, please tell me about it in the comments.



Комментарии
Отправить комментарий