Table bloat? No, never heard...

I think many well-known feature of PostgreSQL, which has the effect of inflating of tables, or table bloat. We know that it manifests itself in case of intensive data updates as frequent UPDATE and INSERT/DELETE operations. As a result of this inflation decreases the performance. Consider why this is happening and how this can be dealt with.
Tables in PostgreSQL are presented in pages of size 8Kb, in which the records are located. When one page is completely filled with entries to the table add a new page. When udeleni records by using the DELETE or modify it with a UPDATE, the place where was the old record cannot be re-used immediately. For this cleaning process autovacuum or VACUUM command, runs on the changed pages and marks that place as free, after which a new entry can safely be recorded in this place. If autovacuum is unable to cope, for example as a result of active changes, more data or simply due to bad settings, the table will unnecessarily be added to new pages as new records arrive. And even after cleaning comes to our deleted records, the new page will remain. It turns out that the table becomes more rarefied in terms of density records. This is called the effect of inflating of tables table bloat.
The cleaning procedure, autovacuum or VACUUM can reduce table size by removing completely blank page, but only on the condition that they are at the end of the table. To minimize a table in PostgreSQL has a VACUUM FULL or CLUSTER, but both these techniques require heavy and long locks on the table that is not always a suitable solution.
Consider one of the solutions. When you update a record using UPDATE, if the table has free space, the new version will go exactly in free space, without allocating new pages. Preference is given to the free location closest to the beginning of the table. If you update a table by using so-called fake updates, such some_column = some_column from the last page, at some point, all the records from the last page go into free space in earlier pages of the table. Thus, after several such operations, the last page will be empty and the usual non-blocking VACUUM will be able to cut them off from the table, thereby reducing the size.
In the end, using this technique, it is possible to compress the table, without causing any critical locks, and thus without interfering with other sessions and normal work base.
And now the most important)))) To automate this procedure, there is a utility pgcompactor.
Its main features are:
the
-
the
- requires no dependencies except Perl > =5.8.8, i.e. you can just copy pgcompactor to the server and work with it; the
- works through adapters DBD::Pg, DBD::PgPP or even a standard utility psql, if the first two the server; the
- processing of individual tables, all tables within the schema, database or the entire cluster. the
- possibility to exclude databases, schemas or tables from processing; the
- analysis of the effect of inflating and treatment of only those tables, which present, for more accurate calculations it is recommended to install the extension pgstattuple; the
- analyzing and rebuilding indexes with the effect of inflation; the
- analysis and rebuilding of the unique constraints (unique constraints) and primary keys (primary keys) with the effect of inflation; the
- incremental-use, i.e. you can stop the compression process without compromising anything; the
- dynamic adjustment to the current load of database to not affect the performance of user queries (with the possibility of adjustment at startup); the
- recommendations to administrators, followed by the DDL ready to rebuild database objects that can not be rebuilt automatically.
A couple of examples of usage:
run on all cluster required rebuilding indexes:
# pgcompactor --all --reindex
running on a separate table (rebuilding indexes):
# pgcompactor --reindex --dbname geodata --table cities --verbose info >pgcompactor.log 2>&1
Result:
Table size decreased from 9.2 GB to 5.6 GB. The total size of all indexes dropped from 7.5 GB to 2.8 GB
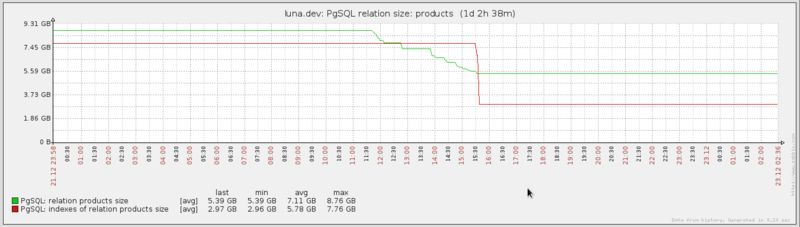
Project URL: github.com/PostgreSQL-Consulting/pgcompacttable
Many thanks to the authors of the utility for their work! This is a really useful tool.
Thank you for your attention!



Комментарии
Отправить комментарий